

Introduction
Over the last few decades, organizations have improved their processes significantly, resulting in increased profits. At the same time, internal documentation has expanded dramatically. Growing volumes of core business and regulatory materials, Commercial Off-The-Shelf (COTS) guides, Software-as-a-Service (SaaS) tech documentation, and other tools have all contributed to this increase.
Employees still face challenges locating essential information due to knowledge silos, time constraints, and team mobility. Retrieval-Augmented Generation (RAG) provides a unified solution by combining existing documentation with advanced retrieval methods to deliver precise, up-to-date answers.
To foster clarity, RAG is not restricted to enterprises; it can be applied at any level, and I believe it offers significant potential benefits for organizations. The remainder of this post focuses on using RAG within enterprises.
In this post, I present RAG fundamentals, demonstrate a LangChain and Facebook AI Similarity Search (FAISS) prototype, examine production deployment strategies, and provide a dos and don’ts guide for RAG projects. LangChain is an open-source framework designed to simplify the development of applications powered by large language models (LLMs).
Why RAG Matters Today
A key limitation of LLMs is their reliance on static training data that ends at a predefined cut-off date. As a result, their responses may not incorporate the most recent information, can sometimes be inaccurate, and on occasion the model may fabricate details. RAG offers a practical solution to this challenge. In the next section, I will review its core concepts.
Here are the real-world drivers for RAG adoption: up-to-date knowledge, domain-specific accuracy, reduced hallucinations, scalable knowledge access, cost efficiency, regulatory compliance and auditability, enhanced user experience, and integration with existing systems (RAG – Amazon).
Key market trends include:
- RAG market size is expected to grow from 1.2 Billion USD in 2024 to 11 Billion USD by 2030, that is growing at CAGR 49% from 2025 to 2030 (Grand View Research).
- The Wall Street Journal (May 2024), says vector database market is expected to grow to $4.3 billion by 2028, from $1.5 billion in 2023.
- As per Menlo Ventures report, 9% of production models were fine-tuned and RAG adoption rate is 51% in 2024.
“RAG bridges the gap between static model knowledge and the dynamic reality of enterprise information”
To understand how RAG delivers these benefits in practice, we need to comprehend its architecture and workflow.
RAG Architecture and Workflow
What is RAG?
RAG is a technique that improves a model’s generation capabilities by retrieving context-specific information from an external source like a vector database. The external source could be an internal knowledge base, previous chat sessions, or the Internet. The term Retrieval-Augmented Generation was coined by Lewis et al. of the Facebook AI Research team in their paper “Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks”.
RAG Architecture
RAG is a three-step process. First, the user prompt is sent to a retriever, which searches an external vector database for relevant context. Second, the prompt and retrieved context are combined and fed into the LLM. Finally, the LLM generates the output.
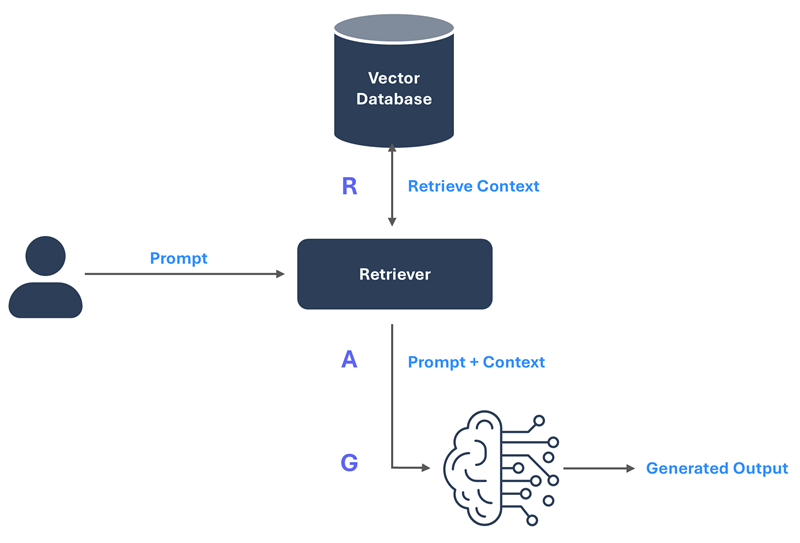
Figure-01: RAG Architecture Diagram
Semantic Search
At the heart of every successful RAG pipeline, Semantic Search is indispensable. Semantic Search is a data-searching technique that focuses on understanding the contextual meaning and intent behind a user’s query, rather than merely matching keywords (Semantic search – Google). While RAG augments language models with external information, Semantic Search complements it by enabling searches based on context. LLMs such as GPT use Semantic Search (RAG – Open AI).
Vector Database
Vector databases form the backbone of RAG systems. Unlike traditional databases that work with structured rows and columns, vector databases store numerical representations of text, referred to as embeddings. These embeddings capture the underlying meaning of the content, making it possible to search based on context rather than exact wording.
When a user submits a query, it is converted into a vector and compared against stored embeddings to retrieve the most relevant chunks. This allows the system to surface meaningful results even if the query uses different language than the original document.
Commonly used vector databases in RAG include FAISS, which is lightweight and suitable for local development, and cloud-based options like Pinecone and Weaviate that offer scalability, high availability, and additional indexing features. The right choice depends on factors such as data volume, latency requirements, and the complexity of the retrieval pipeline.
RAG Pipeline
I will expand on the RAG architecture that was presented as a simplified overview. A full RAG pipeline involves four phases: offline ingestion, indexing, online query and output generation.
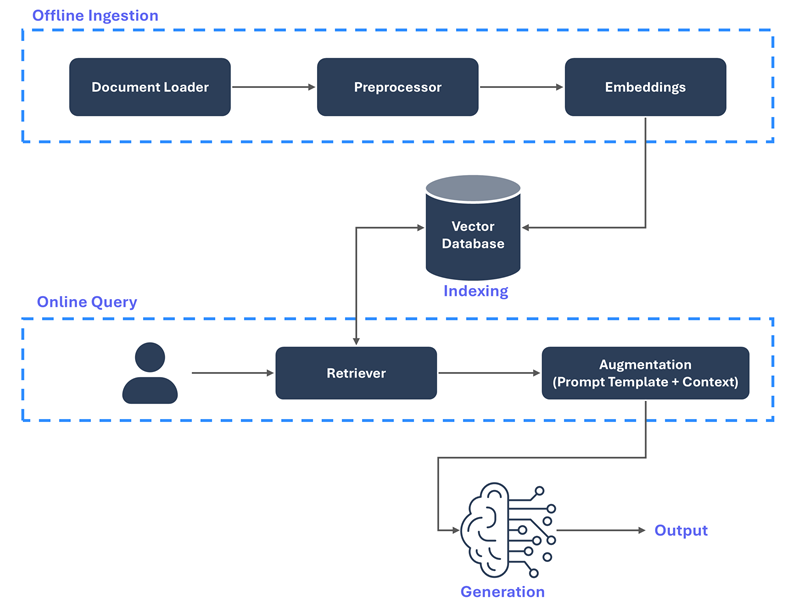
Figure-02: RAG Architecture and Pipeline
Offline ingestion is isolated from the online path. It handles data ingestion, splits documents into manageable chunks, converts each chunk into a fixed-length embedding and captures semantic meaning.
Indexing stores those embeddings in a vector database such as Pinecone or Weaviate and optimises them for fast similarity search.
Online query and output generation follow the flow introduced in the RAG architecture section. The user’s prompt is embedded, relevant chunks are retrieved, the prompt and context are combined and the model generates the final answer.
RAG vs Fine-Tuning
Before we build a RAG system, it’s important to understand how it differs from fine-tuning. Both aim to improve model output, but they do it in very different ways.
RAG does not change a model’s parameters. It improves answers by adding relevant, external context at query time, often from enterprise documents or knowledge bases. This keeps information current and easy to update by re-indexing, without retraining the model. RAG is faster to deploy, easier to maintain, and carries lower compliance risk since sensitive data stays outside the model.
Fine-tuning changes a model’s parameters by training it further on curated datasets. It can refine tone, reasoning style, or output format, and can simplify prompts. However, it does not reliably add new facts, becomes outdated when your information changes, and is more resource-intensive in both time and compute.
For most enterprise use cases, start with RAG. It delivers grounded, up-to-date results quickly and safely. Fine-tuning should be used when strict formatting, domain-specific behaviour, or smaller, faster models are needed. In some scenarios, combining both approaches offers the best outcome.
“RAG is not just about better answers, it is about better decisions”
To understand how these ideas translate into real-world outcomes, the next section walks through a working RAG prototype built with LangChain and FAISS.
Building a LangChain + FAISS RAG Prototype
In this section, I walk through a RAG prototype built using LangChain and FAISS. The full working code is available in the GitHub repository titled “enterprise-rag-langchain-faiss”. Feel free to explore and try it out.
This prototype is designed to answer enterprise-specific questions with accuracy and context. Rather than relying only on a model’s pre-trained knowledge, it retrieves relevant content from a curated set of domain-specific documents before generating a response. For this implementation, I used five publicly available documents from the finance and banking industry.
Setup and Environment
Considering the cost and technical constraints, I have used the Google Colab environment and installed the necessary Python libraries. LangChain serves as the orchestration layer, FAISS provides the vector search capability, and Hugging Face embeddings generate the numerical vector representations of each text chunk. The OpenAI API powers the language model for final answer generation.
If you plan to run this notebook yourself, ensure that Google Drive is mounted so files persist.
While this prototype uses FAISS a local vector store/database for simplicity and reproducibility, enterprise implementations can integrate managed vector databases such as Pinecone or Weaviate to handle larger datasets, ensure high availability, and provide advanced search features. The same RAG architecture discussed here applies to enterprise systems, with only the storage and retrieval backend changing to meet scale and performance requirements.
Data Preparation
I have used five small text files, with content excerpted from the respective official sites. The table below provides an overview of each file’s contents. The curated files are stored in Google Drive, and each document has been split into overlapping chunks to preserve context. The files are available in the GitHub – Data section.
Hugging Face’s all-MiniLM-L6-v2 model then created 384-dimensional embeddings for each chunk, producing a rich semantic representation that FAISS can search effectively.
| Source | Content Overview | File Name |
| Bank for International Settlements (BIS) official site. | Summary of Basel III framework, covering capital requirements, liquidity standards, and risk management objectives. | basel3_overview.txt |
| European Commission / European Banking Authority. | Overview of the Second Payment Services Directive (PSD2), focusing on open banking, payment security, and consumer rights. | psd2_intro.txt |
| Financial Action Task Force (FATF) official site. | High-level summary of FATF Recommendations on anti-money laundering (AML) and combating the financing of terrorism (CFT). | fatf_recs_overview.txt |
| ISO 20022 official documentation. | Explanation of ISO 20022 messaging standard for financial transactions, including its benefits, scope, and adoption timeline. | iso20022_about.txt |
| Open Banking Implementation Entity (OBIE) | Introduction to open banking, its principles, consumer benefits, and ecosystem participants. | open_banking_what_is.txt |
Table-01: Dataset Preparation
Retrieval with FAISS
These embeddings were stored in a FAISS index, enabling rapid similarity search. When a user enters a question, the query is also converted into an embedding and compared against the stored vectors. FAISS quickly identifies the most relevant chunks based on semantic similarity, even if the wording in the query does not match the document text exactly.
In this prototype, the retrieval step typically returns the top three most relevant chunks, ensuring that only high-quality, context-specific content from the curated finance documents is passed forward for answer generation. This selective retrieval helps maintain both speed and accuracy.
Generating Contextual Answers
The retrieved chunks are combined with the user’s original question and sent to the OpenAI GPT model via a LangChain RetrievalQA chain. This ensures the model’s output is grounded in actual source material while leveraging GPT’s language capabilities to produce a clear, coherent, and context-aware answer.
By injecting the retrieved document context directly into the prompt, the model is prevented from relying solely on its pre-trained data. This approach significantly reduces hallucinations and ensures the answer reflects the most up-to-date and relevant information from the domain-specific corpus.
Key Parameters
In this RAG implementation, documents are split into 1,000-character chunks with a 200-character overlap to preserve context across boundaries. Embeddings are generated locally using the all-MiniLM-L6-v2 model and stored in a FAISS for efficient similarity search. Retrieval uses the default FAISS similarity metric to return the most relevant chunks for the user’s query.
The configuration choices in this project directly influence accuracy, speed, and cost. The table below summarises the key parameters used and provides guidance on how they can be tuned for different scenarios.
| Parameter | Purpose | Used in This Project | Tuning Notes |
| Chunk Size | Length of each text segment before embedding. | 1000 | Increase to provide richer context. Decrease for more precise retrieval and lower token usage. |
| Chunk Overlap | Number of characters overlapped between chunks. | 200 | Increase if important content spans across chunks. Decrease to reduce duplication in results. |
| Embedding Model | Converts text into vector representations. | sentence-transformers/all-MiniLM-L6-v2 | Choose a higher-dimensional model such as all-mpnet-base-v2 for improved accuracy, depending on available storage and compute capacity. |
| Vector Database | Stores embeddings, enables search. | FAISS (local) | Use managed options like Pinecone, Weaviate, or Milvus if scalability, availability, and operational simplicity are important. |
| Similarity Metric | Compares vectors | L2 (default) | Use cosine similarity for semantic tasks. Dot product may perform better with specific model architectures. |
| Top-K Retrieval | Number of most similar chunks retrieved. | Default (≈4) | Increase to improve context recall. Reduce to optimise latency and prompt token limits. |
| Retrieval Strategy | How results are selected. | Standard similarity search | Consider using MMR to limit redundancy and introduce variety into the retrieved chunks. |
Table-02: Core Parameters to Evaluate
Deploying RAG: Real-World Considerations
Deploying RAG-enabled applications in production follows many of the same principles as other complex enterprise systems. However, there are a few additional factors that require close attention during deployment.
- Vector database growth and cost: Storing embeddings over time can drive up storage costs. Monitor usage regularly and set up lifecycle policies to archive or remove outdated vectors.
- Embedding refresh cycles: Set a schedule to regenerate embeddings so that retrieval remains accurate while avoiding unnecessary compute overhead.
- Latency trade-offs: Balance how much context is retrieved with how quickly the model can respond, keeping user experience in mind.
- Context window management: Optimise the length and structure of retrieved content to ensure it fits within the model’s context window without truncation or token overflow.
- Security risks in retrieval: Limit access to the vector store and retrieval pipeline to prevent accidental exposure of sensitive information.
- Monitoring retrieval-specific metrics: Track metrics such as retrieval hit rate, response accuracy, and hallucination frequency. Early visibility into these signals helps maintain system performance.
In enterprise environments, cost and security considerations are directly influenced by architectural decisions. For compute, serverless or on-demand GPU configurations are often more efficient than keeping hardware running continuously. When demand is low, idle resources can be scaled down, and burst capacity can be added only when needed.
API usage costs can be optimised by caching. Embeddings can be stored locally, and previous query-to-response mappings can be temporarily cached with a time-to-live policy. This avoids unnecessary calls when the same prompt and context are reused, while keeping the content fresh.
If the LLM is hosted within your network, data protection becomes more straightforward, since everything stays in a controlled environment. However, when using external APIs, additional safeguards are essential. Keep the vector database and retrieval layers within your infrastructure, and send only the minimum required content to the LLM. Use private endpoints or VPC connections, disable data retention on provider platforms, and scrub sensitive data before sending it externally. Apply tokenisation, encryption, least-privilege access policies, and audit logs to minimise risk and meet compliance standards.
When to Adopt RAG
Enterprises should give consideration for RAG when the business-critical information changes frequently, where accuracy is non-negotiable, and also if they want to address operational gaps to optimise efficiency. These scenarios are common in compliance-heavy domains such as finance, legal, healthcare, and policy, where incorrect or outdated responses carry regulatory or reputational risks.
“Enterprises adopting RAG can turn hidden knowledge silos into operational advantages”
RAG is a compelling choice when large volumes of internal documentation such as product manuals, compliance updates, technical standards, and project wiki bases remain underused. In such cases, RAG can be instrumental in contextualising relevant information across silos and speeding up decision-making by reducing the time spent searching for answers. RAG can also outweigh the benefits of fine-tuning in situations where the model needs to stay current with frequent external or internal updates.
It is important to note that RAG may not be the best option if the data is static and rarely updated. It may also retrieve noise if the source documents are unstructured, low-quality, or inconsistent. The recommended approach is to run a pilot implementation and decide based on a cost-benefit analysis.
The following quick check can help determine whether RAG is the right fit for your enterprise use case.
| Question | Lean Towards RAG | Consider Alternatives |
| Does the source information change frequently and require real-time accuracy? | Yes | No |
| Does the source information change frequently and require real-time accuracy? | Yes | No |
| Would fine-tuning be too costly or impractical to keep the model current? | Yes | No |
Table-03: Adoption Criteria
RAG Implementation: Dos & Don’ts
Even with a solid architecture and a working prototype, a RAG system can fall short if it is not implemented with operational discipline. Long-term success depends not just on building the solution, but on how well it is maintained, secured, and scaled over time. The following practices are based on real-world experience and are intended to help avoid common pitfalls. Applying them will improve the accuracy, efficiency, and reliability of your RAG implementation.
Dos
- Reindex at regular intervals so the vector store reflects the latest information.
- Include human-in-the-loop checks to verify the quality and relevance of retrieval results.
- Adjust chunk size and overlap to strike the right balance between context depth and retrieval precision.
- Structure prompts in a way that clearly incorporates the retrieved context into the response.
- Protect the entire pipeline by encrypting vectors, anonymising sensitive content, and restricting access to embedding and retrieval services.
Don’ts
- Avoid over-chunking documents, as it can break context and degrade the quality of the results.
- Do not let embeddings become outdated, especially in domains where content changes frequently.
- Never store sensitive information without proper safeguards such as encryption or tokenisation.
- Don’t assume retrieval alone is enough; always validate the reasoning in the model’s response.
- Don’t overlook latency concerns caused by complex retrieval paths or large indexes.
“RAG should be a living system, maintained, monitored, and continuously improved”
Conclusion
To sum up, RAG offers a practical way for enterprises to unlock the full value of their internal knowledge. By combining retrieval techniques with the generative power of LLMs, it delivers accurate, grounded, and context-aware responses that adapt to changing information needs.
The LangChain and FAISS example in this post demonstrates that RAG can be built with accessible tools and extended to enterprise-grade scale. The key lies not just in building the system, but in how it is maintained. This includes keeping embeddings current, securing the retrieval pipeline, and optimising overall performance.
Organisations that adopt RAG strategically will be better equipped to improve decision-making, streamline operations, and stay competitive in environments where speed and accuracy matter. Whether starting with a pilot or integrating into production systems, the impact can be significant when done right.