

Introduction
In today’s AI-driven world, many may not realize that products like Amazon’s Alexa and Apple’s Siri are powered by Natural Language Processing (NLP). NLP is a subfield of artificial intelligence that uses machine learning to understand and communicate using human language. It extracts valuable insights from data such as customer reviews, social media posts, and news articles.
Before 2018, understanding text context in both directions, left to right and right to left, posed a significant challenge for NLP models. Google’s Bidirectional Encoder Representations from Transformers (BERT) introduced a breakthrough by addressing this issue, enabling models to better identify patterns, trends, and sentiments in text.
Organizations widely employ models like BERT for sentiment analysis, which can accurately classify complex and natural language data using advanced statistical and deep learning techniques.
In this blog post, I apply BERT to perform sentiment analysis on finance related data extracted from Kaggle, containing user expressed opinions. I discuss the dataset, data preprocessing, technical approach, results, and analysis. As a heads-up, this post includes code, and I have aimed to balance the content to benefit both developers and tech leaders. The full code is available in the GitHub repository.
Why Fine-Tuning BERT
To avoid any confusion, this post focuses exclusively on fine-tuning a pre-trained BERT model for a sentiment analysis task, rather than on methods for speeding up or compressing the model. Techniques such as pruning, quantization, and knowledge distillation will be covered in a later post.
“Fine-tuning allows you to adapt powerful pretrained models to your specific domain, saving time and compute.”
BERT Architecture
As mentioned earlier, BERT uses bidirectional context understanding of sentences, meaning it processes text both from left to right and right to left. BERT is built on top of the Transformer encoder. For more details on the Transformer architecture, please refer to my blog Transformer Revolution.
This bidirectional capability enables BERT to better capture language nuances than previous approaches, improving performance in tasks such as question answering, sentiment analysis, and classification.
The BERT architecture consists of three main components:
- Input Embeddings
- Transformer Encoder
- Output Head
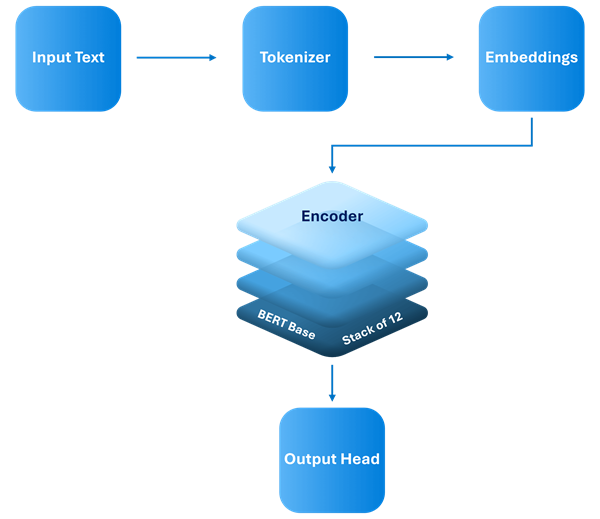
Figure-01: Simplified BERT Architecture
Input Embeddings
The input embeddings in BERT combine three types of embeddings to represent each token in the input text. Token embeddings represent each individual token (or word) as a vector. Segment embeddings differentiate between different segments, such as sentence A and sentence B, which is useful for tasks involving sentence pairs. Positional embeddings encode the position of each token in the sequence, helping the model capture the order of information.
Transformer Encoder
The Transformer encoder is composed of multiple layers, each containing two key components. The first is multi-head self-attention, which allows every token to attend to every other token in the sequence. Multiple attention heads capture different types of relationships between tokens, enabling BERT’s powerful bidirectional understanding of context. The second component is a feed-forward neural network, which is a fully connected layer applied after the self-attention mechanism to further process the information.
Output Head
Depending on the task, BERT adds specific output layers on top of the encoder stack. For example, a classification layer is used for sentence-level classification, while a token-level classifier is applied for named entity recognition.
Why BERT for Sentiment Analysis
There are different NLP techniques to perform sentiment analysis such as Bag of Words (BoW), Term Frequency-Inverse Document Frequency (TF-IDF), Word Embeddings (Word2Vec, GloVe), Recurrent Neural Networks (RNN), Embeddings from Language Model (ELMo) , Convolutional Neural Networks (CNN), Rule-based and Lexicon-based methods, and more. However, each approach has its own limitations, such as ignoring context, not capturing nuances, slow training times, and more. Please see the table below that provides an overview of key challenges faced by each method.
| Model | Key Challenges |
| Bag of Words (BoW) | Ignores context and word order |
| Term Frequency-Inverse Document Frequency (TF-IDF) | Ignores context and word order |
| Word Embeddings (Word2Vec, GloVe) | Static embeddings and unable to capture context. Lexical ambiguity. |
| Recurrent Neural Networks (RNN) | Difficult for long sequences and slow |
| Embeddings From Language Model (ELMo) | Bi-directional and based on Long Short-Term Memory (LSTM) architecture. Struggles with long-range dependencies |
| Convolutional Neural Networks (CNN) | Limited long-range context |
| Rule-based & Lexicon-based Methods | Rule-based & Lexicon-based Methods |
Table-01: Available Models and Their Challenges in Sentiment Analysis
BERT untangles most of the difficulties mentioned above due to its bi-directional ability, improved context understanding, and capacity to handle long-range dependencies. Similarly, the ELMo model has bi-directional capability and is based on LSTM architecture. However, BERT has the edge because it relies on the powerful self-attention mechanism of the Transformer architecture.
Further, BERT is pre-trained on massive amounts of text data and it allows to learn general language representation. Kindly be informed, BERT is one of the best model available for sentiment analysis, and it has its own limitations like compute heavy and data hungry.
The key takeaway is this: imagine you have a problem to solve, similar to sentiment analysis, at your organization. Evaluating the available models and then performing a proof of concept is a more efficient way to spend the available budget. Once this stage is passed, the next step is integrating the models into your system architecture, most likely via microservices or agents.
“Evaluate models the same way you evaluate your tech stack.”
Why Fine-Tune Pretrained Models
In machine learning, pre-training refers to the initial process of training a model on a wide range of datasets. BERT has been trained on Wikipedia (2,500 million words) and BookCorpus (800 million words), and the model focuses on text data. Since the model is pre-trained, it is already capable of performing tasks such as text classification and sentiment analysis.
In our case, we will perform sentiment analysis on financial data, which means we inherit BERT’s capabilities for analysis. Along with leveraging prior knowledge, other cost and time benefits include faster training times, reduced compute costs, and better performance on specific tasks.
Problem Definition
Having discussed the context and theoretical aspects of the BERT model, the remainder of this post focuses on sentiment analysis of financial data extracted from Kaggle. The goal of fine-tuning the BERT model is to accurately interpret the sentiment of user opinions collected from various channels while accounting for challenges such as financial industry jargon, ambiguous language, and class imbalance.
Dataset
The dataset is sourced from Kaggle and contains financial texts related to company-specific news, stock price movements, trading information, market reports, financial transactions and deals, as well as market analyst opinions. The file includes two columns: sentences and sentiments. The sentences consist of short text snippets, while the sentiment reflects the author’s view and is categorized as positive, neutral, or negative across a total of 5,842 entries.
Below is an excerpt from the dataset for reference (GitHub – Raw Data),
| Sentences | Sentiment |
| Operating profit rose to 22.1 mln eur from 19.9 mln | Positive |
| The company closed last year with a turnover of about four million euros | Neutral |
| Operating profit decreased to nearly EUR 1.7 mn , however | Negative |
Table-02: Example Sentences and Sentiments
Challenges
Each domain and problem presents its own unique challenges. For clarity, I have summarized some of the key challenges commonly encountered in financial sentiment analysis in the table below.
| Challenges in Financial Sentiment | Example | Explanation |
| Domain specific jargon and terminology | $AAPL shares surged after the earnings call | Ticker symbol and company-specific terms require domain knowledge. |
| Ambiguity and nuance in sentiment | Revenue was slightly below expectations. | Ticker symbol and company-specific terms require domain knowledge. |
| Class imbalance in sentiment distribution | Dataset has 60% neutral sentences, 25% positive, and 15% negative | Neutral class dominates, potentially biasing the model. |
| Short text length and context limitations | Q2 profits up. | Very brief, lacking context to fully judge sentiment. |
| Use of figurative language or market jargon | The stock is in the doghouse after the scandal. | Idiom ‘in the doghouse’ indicates trouble but might confuse models. |
Table-03: Challenges in Sentiment Analysis
Fine-Tuning BERT: Data and Training Pipeline
Before we delve into the details of fine-tuning, I want to present a high-level workflow of the process so you find it useful and can adapt a similar approach to your needs. We will explore each step in this section.
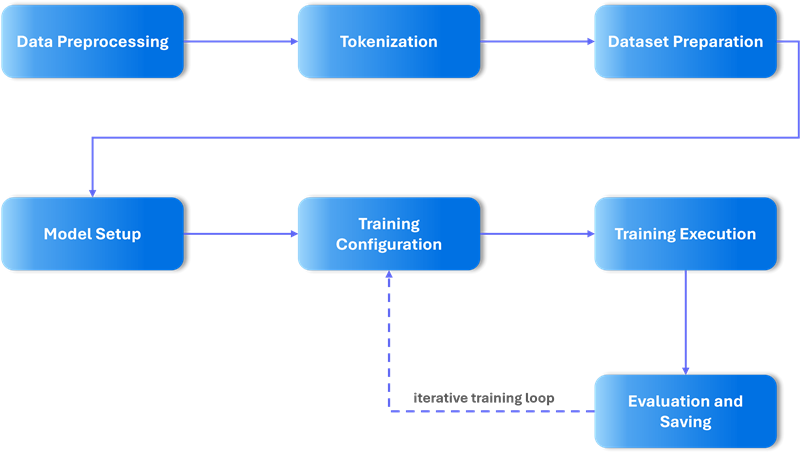
Figure-02: Training Pipeline
Libraries and Platform
For clarity, this fine-tuning project has been implemented using popular Python libraries. The following sections include code snippets that highlight key parts of the implementation; kindly refer to the Git repository mentioned below for the full working code and dependencies.
PyTorch is used for dataset handling, data loader utilities, model building, and training. Hugging Face’s Transformers API provides pretrained BERT tokenizers and model classes. Pandas is used for data loading, manipulation, and preprocessing. Scikit-Learn is employed for label encoding and evaluation metrics.
Since fine-tuning is GPU intensive, I used Google Colab, which is free. The only limitation is that Colab sessions are not persistent, meaning you need to save your work to a mounted drive of your choice.
If you want to recreate this project, the source code is available at bert-financial-sentiment-classifier. For those interested in learning fine-tuning, I recommend going through Hugging Face’s Large Language Model course.
Data Preprocessing
Data preprocessing is a crucial step as the quality of data directly affects model training. Noisy elements such as inconsistent text normalization, URLs, ticker symbols, special characters, errors, and other irrelevant tokens that do not contribute to sentiment analysis must be handled during this phase.
In the dataset I have used, the sentiment labels positive, neutral, and negative are encoded as 2, 1, and 0 respectively. This encoding allows the model to learn effectively from the labels.
from sklearn.preprocessing import LabelEncoder
import pandas as pd
# Initialize Label Encoder
le = LabelEncoder()
# Fit and transform the 'Sentiment' column to numeric labels
df['label'] = le.fit_transform(df['Sentiment'])
# Check the mapping
label_mapping = dict(zip(le.classes_, le.transform(le.classes_)))The goal here is to clean the raw sentences and encode the sentiment labels before the tokenization phase.
“Preprocessing and tokenization are crucial foundations for effective model training“
Tokenization
As discussed in the BERT architecture overview, the text must be converted into numerical representations so the model’s embedding layer can process it effectively.
'''
Tokenize Texts
Tokenize 'cleaned_sentence' column in Train, Validation, and Test dataframes.
'''
def tokenize_texts(texts, max_length=128):
return tokenizer(
list(texts), # list of texts
padding='max_length', # pad all to max_length
truncation=True, # truncate longer texts
max_length=max_length, # max token length
return_tensors='pt' # PyTorch tensors
)
train_encodings = tokenize_texts(train_df['cleaned_sentence'])
val_encodings = tokenize_texts(val_df['cleaned_sentence'])
test_encodings = tokenize_texts(test_df['cleaned_sentence'])Dataset Preparation
Now that the raw financial sentences have been cleaned and tokenized, the processed data must be organized so that machine learning tools can efficiently ingest and process it. In NLP tasks, the encoded labels and tokens are wrapped using PyTorch into custom dataset classes. These classes handle data indexing and batching, and provide access to input features and targets. Here, input features refer to token IDs and attention masks, while targets correspond to sentiment labels used for supervised learning.
from torch.utils.data import Dataset
class SentimentDataset(Dataset):
"""
Custom PyTorch Dataset for handling tokenized inputs and labels for sentiment analysis.
Allows easy batching and data loading during training and evaluation.
"""
def __init__(self, encodings, labels):
"""
Args:
encodings (dict): Tokenized inputs like input_ids and attention_mask (PyTorch tensors).
labels (torch.Tensor): Corresponding labels tensor.
"""
self.encodings = encodings
self.labels = labels
def __getitem__(self, idx):
"""
Retrieve a single sample by index.
Returns:
dict: Tokenized inputs and label for the given index.
"""
item = {key: val[idx] for key, val in self.encodings.items()}
item['labels'] = self.labels[idx]
return item
def __len__(self):
# Returns the total number of samples.
return len(self.labels)
# Create Dataset objects for train, validation, and test splits.
train_dataset = SentimentDataset(train_encodings, train_labels)
val_dataset = SentimentDataset(val_encodings, val_labels)
test_dataset = SentimentDataset(test_encodings, test_labels)
Scikit-learn is used for stratified splitting, which divides the dataset into training, validation, and test sets while preserving the original distribution of sentiment categories.
Following standard practices, indexing and batching help the model process data efficiently and handle large datasets by loading data in manageable chunks. The dataset class also provides modularity, making the code easier to maintain and reuse, while offering a clean interface to access data.
The data is split as follows:
- Training set: 72%
- Validation set: 13%
- Test set: 15%
The validation set is used during model development and training to tune and evaluate the model, while the test set is reserved for a final unbiased assessment of the model’s performance after training is complete
Model Setup
As noted earlier, the fine-tuning is performed on a pretrained BERT model loaded through Hugging Face’s Transformers library. Specifically, I use BertForSequenceClassification, which adds a classification layer on top of BERT suited for sentiment analysis. Given that the dataset consists of three sentiment categories, positive, neutral, and negative, the model is configured to predict three output labels.
from transformers import BertForSequenceClassification
# Load the pretrained BERT base model with a classification head for 3 sentiment classes: negative, neutral, positive.
model = BertForSequenceClassification.from_pretrained('bert-base-uncased', num_labels=3)Training Configuration
Imagine an automobile engineer who tweaks different parts of an engine to find the best balance between performance and efficiency, such as miles per gallon. Model tuning is very much the same. The tuning objectives are guided by the tasks and available budget.
For example, a medical diagnosis will require 99% accuracy, while a recommendation system can accept less accuracy in exchange for better speed. Also, increasing accuracy from a certain level to 99% may not always be the right choice as it can cause overfitting, where the model starts memorizing the training data, wasting resources and adversely impacting return on investment.
Here, I leverage Hugging Face’s Trainer API, which simplifies the fine-tuning process by handling the training and evaluation loops and managing configurations behind the scenes. To mention one example, the Adaptive Learning Rate Optimization algorithm (AdamW) is used; it improves model generalization and separates weight decay from the gradient update.
Below are the key parameters I configured as part of the fine-tuning process:
- Batch Size: Controls training speed and memory usage; larger batches are faster but need more memory.
- Learning Rate: Determines how fast the model updates weights during training.
- Weight Decay: Regularizes the model to reduce overfitting and improve generalization.
- Evaluation and Saving Strategy: Sets how often the model is evaluated and checkpoints are saved.
- Best Model Loading: Automatically saves and loads the best model based on validation performance.
# Define training arguments for the Hugging Face Trainer API
training_args = TrainingArguments(
output_dir='/content/drive/MyDrive/bert-financial-sentiment-classifier/results', # output directory
num_train_epochs=3, # number of training epochs
per_device_train_batch_size=16, # training batch size per device
per_device_eval_batch_size=16, # evaluation batch size
eval_strategy='epoch', # evaluate at the end of each epoch
save_strategy='epoch', # save checkpoint every epoch
learning_rate=5e-5, # learning rate
weight_decay=0.01, # weight decay
logging_dir='/content/drive/MyDrive/bert-financial-sentiment-classifier/logs', # logging directory
logging_steps=50, # log every 50 steps
load_best_model_at_end=True, # load best model at end of training
metric_for_best_model='accuracy' # metric to use for best model selection
)Training Execution
Once the model and training settings are ready, the training starts using Hugging Face’s Trainer API. This means creating a Trainer object with the model, training parameters, datasets, and evaluation metrics. Running the train() method begins the fine-tuning, running for the set number of epochs, with periodic evaluation and automatic saving of checkpoints. Here, the training runs on a Colab session, where I use the available GPU to speed up processing.
# Initialize the Hugging Face Trainer with model, datasets, tokenizer, and evaluation metrics.
trainer = Trainer(
model=model,
args=training_args,
train_dataset=train_dataset,
eval_dataset=val_dataset,
tokenizer=tokenizer,
compute_metrics=compute_metrics
)
# Start training process
trainer.train()Results and Analysis
After training, the model reached around 80% accuracy on the validation set, showing it is able to reasonably identify sentiment in financial text. Besides accuracy, I also monitored precision, recall, and F1-score to get a clearer picture of how the model performs across the different sentiment categories.
| Metrics |
Value |
| Accuracy | 80.27% |
| F1-Score | 80.94% |
| Precision | 82.36% |
| Recall | 80.27% |
Table-04: Results
“Pushing for perfection can lead to overfitting and lost effort.”
To help interpret the results, accuracy is the simplest metric, calculated as the proportion of correct predictions. A high precision score means the model’s positive predictions are actually correct. Similarly, recall (also called sensitivity) measures how well the model identifies most of the positive cases. The F1-score reflects the overall performance of the model by balancing precision and recall.
The F1-score is important given the class imbalance often found in financial sentiment data. Together, these metrics indicate the model is not biased toward any particular sentiment and generalizes well.
If you notice accuracy and recall have the same value, it is due to micro-averaging. Micro-averaging calculates overall performance metrics such as precision, recall, and F1-score by considering all individual predictions across all classes together. In multi-class problems like sentiment analysis with positive, neutral, and negative classes, micro-averaging is commonly used. As a result, accuracy and recall end up with the same value.
I decided to stop training once the accuracy and other metrics levelled off near 80%. Continuing further risked overfitting and demanded much more compute power, which wasn’t practical as I am capped with GPU resources.
Overall, these results strike a good balance between performance and resource use, making the model fit for purpose in domain-specific sentiment analysis.
Conclusion
The key point here is to clearly define the problem you want to solve and evaluate models based on that specific task. It’s not about using the biggest or general purpose model by default but choosing what works best for your needs. In financial sentiment analysis, adapting pre-trained BERT model is effective, as this model has been devised to solve text related tasks.
It is paramount to get the data right through preprocessing, tokenization, and proper dataset preparation. Using pretrained models like BERT and setting them up carefully lets you adapt powerful language tools to your domain. Trying to push accuracy too high can cause overfitting and drain your time and computational resources. It’s advisable to monitor metrics like accuracy, precision, recall, and F1-score, and find an optimal balance that accounts for resource costs.
Once you have done your evaluation, build a proof of concept and integrate the model into your system in a loosely coupled way. This makes your solution flexible and easier to update as things change.
Would you choose to leverage pretrained models or build one from scratch?