

Introduction
Models are no longer confined to academic or data science domains; they now form the backbone of software systems that predict, optimize, and enable strategic decision making across businesses. Historically, models and software were viewed as separate domains, even though software has relied on models for over a decade. However, this distinction is rapidly fading.
Models have become foundational components in delivering intelligent software. No longer limited to mathematical theory, they are now integral to modern software architecture. From fraud detection systems to personalized recommendation engines and intelligent chatbots, models power critical software features that shape user experiences and business outcomes.
This post will show how models, from traditional to foundation models, are the core engines powering intelligent, scalable software systems today.
What are Models?
In simple terms, a model is a simplified representation or abstraction of a real world system, concept, or process. It captures the essential features and relationships to help us understand, analyze, predict, or communicate about complex phenomena without including every detail (Stanford Encyclopedia).
-
Purpose of Models
Models serve as approximations, focusing on the key aspects that matter most rather than replicating reality perfectly. This simplification allows us to analyze and predict outcomes without being overwhelmed by complexity. For example, weather models use mathematical equations to approximate atmospheric conditions and forecast weather patterns.
-
Types of Models
At a high level, models can be broadly categorized into three types: traditional models, machine learning models, and artificial intelligence (AI) models.
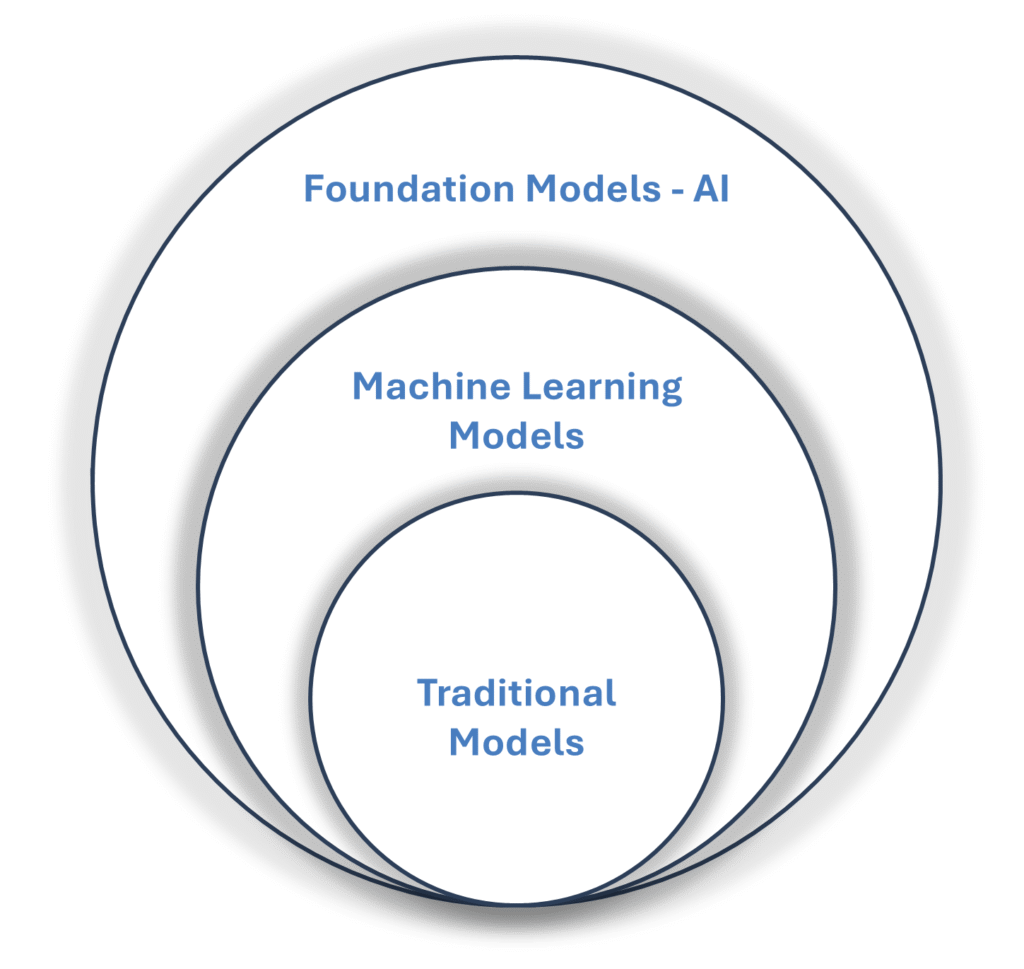
Figure-01: Types of Models
-
- Traditional models rely on explicit mathematical formulas or logical rules to produce deterministic outcomes (Science Direct).
-
- Machine learning models identify patterns in data and use these to make predictions or classifications, adapting as they learn from more examples (IBM – Machine Learning).
-
- AI models cover a broader spectrum, encompassing machine learning and extending to complex architectures that emulate aspects of human intelligence such as reasoning, perception, and generative capabilities. These models often underpin advanced systems like natural language processors, computer vision tools, and foundation models, which serve as versatile bases for multiple downstream tasks (IBM – AI Models).
Recent advancements have introduced foundation models, a new paradigm defined by large scale AI systems trained on vast, diverse data. These models are versatile and adaptable, capable of powering many AI applications through fine tuning or prompt engineering. Think of foundation models like a powerful engine that quietly drives many intelligent software systems behind the scenes.
“Traditional models are narrow, task specific, and trained on limited datasets. In contrast, foundation models are large scale and pre trained on vast, diverse data.”
To better appreciate their impact, it’s important to understand how foundation models differ from traditional models.
-
Traditional vs. Foundation Models
Having introduced foundation models, it’s important to clarify how they differ from traditional models. This section focuses on comparing these two, as the term “model” can have different meanings depending on context.
Traditional models include mathematical techniques such as linear regression and differential equations, as well as statistical methods like generalized linear models and hypothesis testing. These models are generally narrow in scope, designed for specific tasks, and trained on relatively modest datasets.
In contrast, foundation models leverage pre training on massive, diverse datasets. Examples include GPT (language generation), BERT (language understanding), and LLaMA (large language model by Meta). Their applications span natural language processing, code generation, and vision tasks, enabling the creation of intelligent systems. Foundation models typically require fine tuning or prompt engineering to adapt to specific applications (Google – Artificial Intelligence).
Recognizing this distinction is crucial because foundation models represent a new backbone for AI driven software, enabling capabilities far beyond traditional models. Moving forward, I will use the terms “foundation models” and “AI models” interchangeably for simplicity.
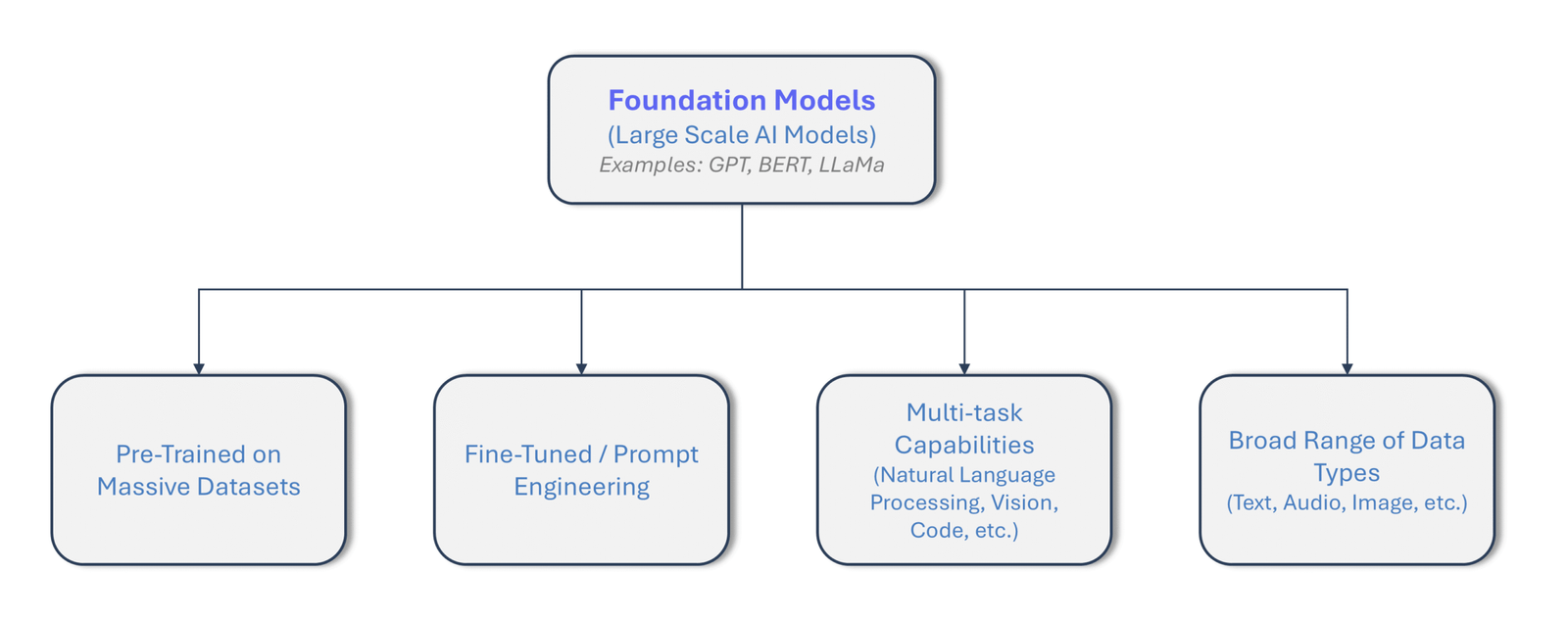
Figure-02: Foundation Models
Foundations of Models
To set expectations: this section covers the core foundations of modeling, including some technical concepts, so it’s dense but essential.
-
Mathematical and Statistical Underpinnings
Machine learning models rely heavily on linear algebra for data manipulation and transformation. Core constructs like vectors, matrices, and tensors represent both data points and model parameters. Matrices, in particular, are essential for operations such as multiplication used to process inputs in neural networks.
Linear algebra acts as the language that enables neural networks to efficiently process and transform data. It is integral throughout the training process, especially for adjusting weights using techniques like backpropagation.
Calculus also plays a vital role in machine learning and AI, supporting essential operations involved in training, learning, and improving models. Key concepts include optimization, gradient descent, and backpropagation within neural networks.

Figure-03: Mathematical Foundations of Models
Information theory provides a mathematical framework to understand and quantify data, including how it is transmitted and processed by AI systems. For example, gradient descent helps the model “learn” by incrementally reducing errors, much like tuning a musical instrument to the right pitch.
Optimization is the process of identifying the best solution to a problem, with gradient descent being one widely used algorithm. Backpropagation trains neural networks by calculating and adjusting weights and biases to minimize errors.
Managing uncertainty and enabling data driven decision making are accomplished using probability and statistical frameworks. Techniques such as hypothesis testing are fundamental for making inferences from data, validating assumptions, and quantifying uncertainty in predictions.
Additionally, discrete mathematics plays a foundational role in modeling relationships and logical structures within AI systems.
-
Data Representation and Processing
Data preprocessing techniques like normalization, feature engineering, and dimensionality reduction are crucial for improving model accuracy and performance. These methods ensure data quality, reduce noise, and make data more suitable for machine learning algorithms. They also streamline analysis and support better decision making.
Normalization standardizes numerical data within a specific range, preventing outliers from dominating the learning process. Think of it as tuning input features so they “speak the same language” before the model learns from them.
“Data Preprocessing: Quality Input Data Directly Impacts Business Success”
Feature engineering involves creating or modifying features to improve model performance. This can include combining features or introducing interaction terms. Well engineered features capture underlying data relationships and lead to more accurate predictions.
Dimensionality reduction reduces the number of features while retaining the most important information. This simplifies models, lowers computational cost, and helps prevent overfitting due to irrelevant features. For example, in image recognition, these techniques help models focus on meaningful visual patterns instead of every pixel.
-
Assumptions and Simplifications
Model assumptions such as linearity, stationarity, and independence present technical challenges in model building. Violations can lead to inaccurate predictions, biased results, and difficulty interpreting outputs. Addressing these requires careful data analysis, model selection, and data transformation.
Real world relationships are rarely perfectly linear. For example, the link between advertising spend and sales may be non linear. Transforming variables or selecting models that handle non linearity can help.
Stationarity assumes time series data characteristics remain constant over time. However, stock prices, for example, typically show trends and fluctuations. Testing for stationarity, transforming data, or using non stationary models can mitigate errors in forecasting.
Independence in linear regression means errors do not predict each other. When errors are dependent, techniques such as residual analysis, autocorrelation correction, or specialized models can address these issues.
“Ignoring Model Assumptions Can Lead to Costly Prediction Errors”
-
Algorithms and Computational Complexity
Algorithms are the core instructions enabling machines to process information, learn from data, and make decisions.
Machine learning algorithms generally fall into four categories: supervised, unsupervised, semi supervised, and reinforcement learning.
-
- Supervised learning uses labelled data to solve classification (assigning data to categories) and regression (modeling relationships) problems.
-
- Unsupervised learning discovers patterns in unlabelled data, useful for clustering or association when inherent groupings are unknown.
-
- Semi supervised learning combines aspects of both.
-
- Reinforcement learning trains agents using rewards and penalties, mimicking human learning.
For a deeper dive, resources like IBM’s Machine Learning Algorithms provide detailed explanations.
Computational complexity measures the time and memory an algorithm requires relative to input size, directly impacting model scalability and runtime. Efficient algorithms balance predictive accuracy with computational cost to operate effectively within resource constraints. For instance, a model taking days to train may be impractical for rapid business decisions.
Building Models: The Process
Building on the theoretical foundation laid earlier, imagine that building models closely mirrors the software development lifecycle. Software development typically involves requirements gathering, design, development, testing, and deployment. Similarly, model building follows a comparable path: defining the problem statement, preparing data pipelines, developing and optimizing the model, validating performance, and deploying the solution.
Before we begin, I won’t delve into the inner workings of models and algorithms. Instead, my goal is to demonstrate how models can be chosen and integrated as part of building intelligent software
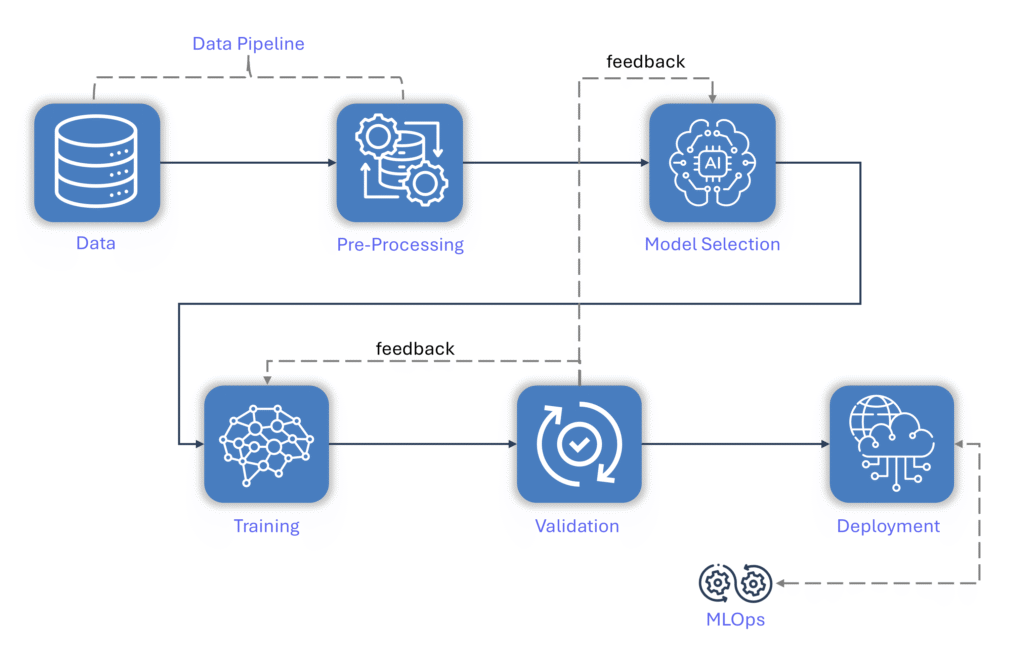
Figure-04: AI Foundation Model Lifecycle
-
Illustrative Problem Statement
For illustration, assume a business aims to predict customer churn determining whether a customer will leave or stay. This translates business requirements into a model that estimates churn probability based on customer data.
-
Data Collection and Preprocessing
Key focus areas during data collection include customer demographics, product usage, financial records, and technical metrics. Addressing missing values thoughtfully during preprocessing is essential. Additional important steps include data cleansing, transformation, feature scaling and engineering, outlier detection, and splitting datasets for training and testing.
Before modeling, ensuring data accuracy, consistency, and completeness is vital. Categorical variables should be encoded appropriately. When data is scarce, augmentation techniques can generate synthetic samples to enrich the dataset.
Data privacy considerations are critical, as lapses can pose significant risks. Most processes are implemented via robust ETL or ELT pipelines using established data management tools.
-
Model Selection and Algorithm Choice
There is no one size fits all model or algorithm; the choice depends on data, business goals, and resources. Common techniques for churn prediction include logistic regression, decision trees, neural networks, and ensemble methods.
It’s important to understand the difference between a model and an algorithm. A model, like a decision tree, makes predictions based on data. An algorithm is the method used to build and improve that model by learning from the data.
For binary outcomes, logistic regression often works well. Decision trees excel when decisions can be broken into binary splits. Neural networks capture complex, non linear data relationships. Ensemble methods combine multiple models to boost accuracy.
For a deeper dive on churn modeling, see “How to Choose the Best Prediction Model for Your Business” by Stripe.
An IEEE study identified Decision Tree Classification, Random Forest, AdaBoost, and XGBoost as top performing algorithms for churn prediction. Evaluating these in context guides informed decisions.
Decision trees function both as models, representing flowchart like decision structures, and as bases for ensemble algorithms like Random Forest and AdaBoost, which use multiple trees for enhanced accuracy.
-
Validation, Cross Validation, and Hyperparameter Tuning
Validation assesses how well a trained model performs on unseen data and detects overfitting.
“Validation and Cross Validation ensure model reliability.”
Cross validation splits data into subsets; the model trains on some and validates on others, estimating generalization and reducing bias.
Hyperparameter tuning is like fine tuning a machine: you don’t change the model or data but adjust external settings (e.g., learning rate, number of trees) to improve performance. As noted, decision trees are models, and “number of trees” refers to how many individual trees vote in ensemble methods.
For explanation, this section focuses on a machine learning model, but the same high level process applies to foundation models, which often involve more complexity like large scale pre training and fine tuning.
Model deployment usually follows a similar path to software package deployment, leveraging organizational tools like containerization, model serving frameworks, and MLOps practices to ensure scalability, monitoring, and governance.
Applications of Models
Over the past decade, enterprises and technology companies have embraced traditional, machine learning, and foundation models. Traditional models power applications such as spam filtering, image recognition, and fraud detection. Machine learning enhances product recommendations, facial recognition, sentiment analysis, and predictive analytics. Foundation models underpin advanced applications including customer support chatbots, language translation, content generation, virtual assistants, and code development.
| Category | Common Applications | Models / Algorithms |
| Traditional Models | Spam filtering, Fraud detection | Rule based filters, Logistic Regression, Decision Trees |
| Machine Learning Models | Recommendations, Facial recognition, Sentiment analysis, Predictive analytics | Collaborative Filtering, Convolutional Neural Networks (CNNs), Recurrent Neural Networks (RNNs), Support Vector Machines (SVMs), Random Forests, Gradient Boosting |
| Foundation Models | Chatbots, Language translation, Content generation, Virtual assistants, Code development | Transformer based Models: GPT, BERT, PaLM, LaMDA, Codex |
Table-01: Applications and Models
-
Models in the AI SDLC
Integrating models into the software development lifecycle requires more than a plug and play approach; it demands continuous refinement across phases and close collaboration among teams.
Consider predictive customer churn as an example, success begins with clear, actionable requirements.
Equally critical is data quality, which hinges on seamless cooperation between data engineering and data science teams. High quality data directly translates into more accurate and reliable model outcomes.
Before implementation, a pre development stage focused on model evaluation is necessary. The development process is iterative, adapting based on feedback from model training, validation, quality engineering, and post deployment monitoring. Monitoring model specific metrics alongside traditional software metrics is crucial for building, delivering, and maintaining sustainable, effective intelligent systems.
-
Integrate or Build: Strategic Model Choice
A critical strategic decision for organizations is whether to build custom AI models or integrate existing solutions, ranging from open source and commercial offerings to API based services.
As detailed in Chip Huyen’s AI Engineering, an open source model is truly “open” only if its training data is publicly available. Open data enables retraining, architectural modifications, and adjustments to training processes. Models released with “open weights” may lack accompanying open datasets, so “open model” should be reserved for those with open data.
Licenses for open weight and open models must be carefully reviewed by CTOs and technical leaders. Key questions include whether commercial use is allowed, if usage restrictions exist, and whether model outputs can train or improve other models.
Commercial models like those from OpenAI are accessed via APIs, with some providers releasing weaker open source versions.
The build versus buy decision is shaped by factors such as data privacy, data lineage (tracking data origin and flow), performance, functionality, cost, control, and on device deployment needs.
-
Engineering for AI System Quality
Beyond traditional software engineering principles like availability, performance, reliability, scalability, and security, AI systems face unique challenges. These include maintaining accuracy, ensuring fairness, managing non deterministic outputs, handling data dependencies, detecting and mitigating model drift (performance degradation over time), providing explainability, and implementing effective retraining to sustain quality. These factors must be integral to your AI engineering efforts.
Challenges of Foundation Models.
Like any emerging technology, foundation models face several significant challenges. According to IBM, the key issues include bias, computational cost, data privacy and intellectual property concerns, environmental impact, and hallucinations.
Bias in foundation models stems from human labelled training data and directly affects the fairness and quality of outputs. Software systems relying on biased models risk reputational damage and, in extreme cases, business viability.
The substantial memory demands and requirement for advanced hardware like GPUs pose barriers, especially for small and medium enterprises. Investments in hardware or cloud services can be costly with uncertain immediate returns, though AI’s transformative potential cannot be ignored.
Training large scale models is energy intensive, contributing to carbon emissions and water consumption, raising environmental concerns.
Data privacy is critical; training on data without consent risks legal exposure. Hallucinations, the generation of inaccurate or fabricated information must be addressed to maintain output reliability.
While the future of foundation models is promising, business leaders must carefully consider these challenges to responsibly harness AI technology.
Future of Foundation Models
We are currently in the era of Artificial Narrow Intelligence (ANI), where AI systems specialize in specific tasks. In the near future, foundation models are expected to evolve with enhanced multimodal capabilities, enabling seamless processing and integration of diverse data types such as text, images, and audio.
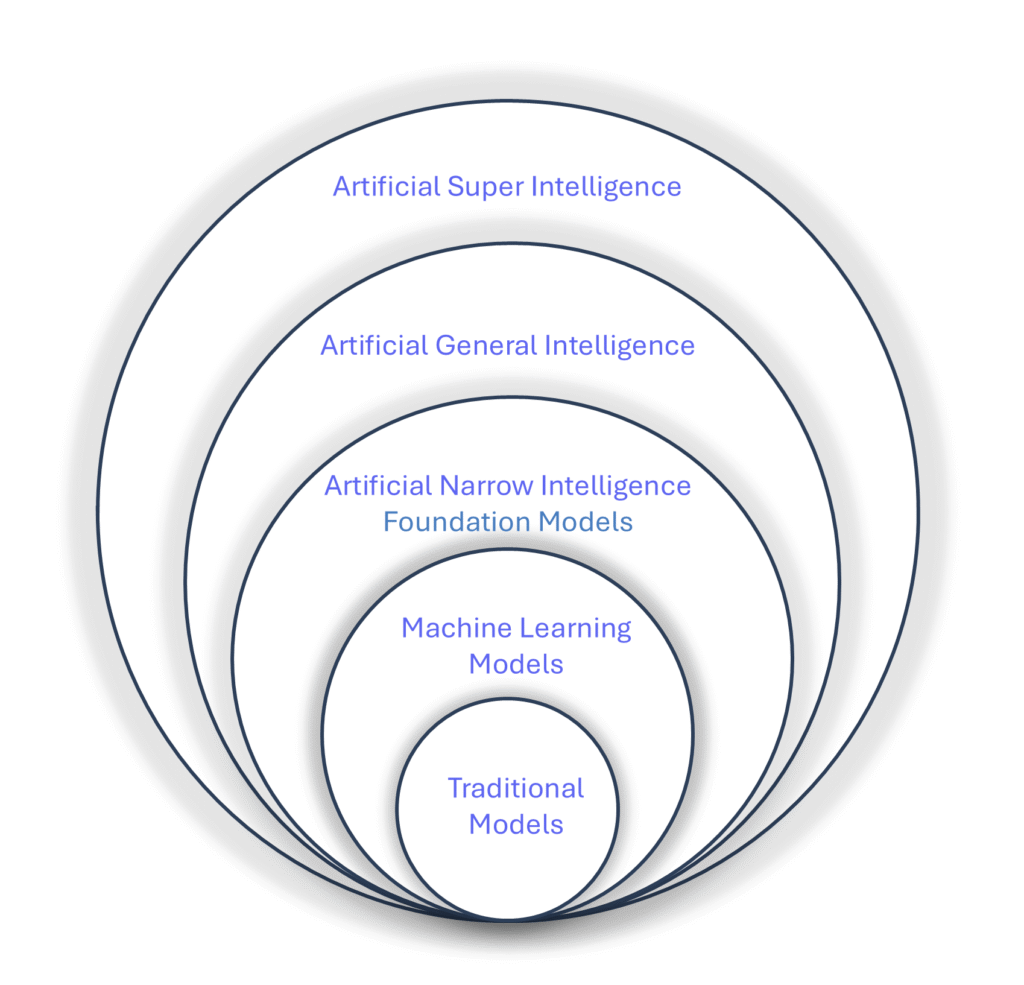
Figure-05: Future of AI and Models
They will also develop the ability to learn dynamically from new data and environments.
Additionally, ongoing research into lightweight models, through techniques like model distillation and pruning, aims to improve computational efficiency and reduce the environmental impact associated with large scale AI training and deployment.
Looking further ahead, the emergence of Artificial General Intelligence (AGI) systems with human like cognitive abilities capable of generalizing across tasks remains a subject of active debate and research. Achieving AGI involves overcoming profound technical and ethical challenges.
Beyond AGI, Artificial Super Intelligence (ASI) could potentially solve problems far beyond human capabilities, although this remains speculative.
Tech leaders such as Google have highlighted the potential of quantum computing, when combined with AI development, to radically accelerate the solving of complex real world problems. As foundation models continue to advance, they are poised to transform industries, driving innovation and reshaping how we interact with technology and data.
Operationalizing Models: MLOps and Beyond
So far, we’ve covered the key theoretical and technical foundations of AI. Now, the question of how to successfully bring AI applications into production is addressed by MLOps.
MLOps, stands for machine learning operations, refers to the comprehensive management of the machine learning lifecycle, from development and deployment to continuous monitoring. It involves several critical activities:
-
- Experiment tracking: Documenting experiments and their results to identify the best performing models.
-
- Model deployment: Deploying models into production environments and integrating them with business applications.
-
- Model monitoring: Continuously tracking model behavior to detect issues or performance degradation.
-
- Model retraining: Updating models with new data to maintain or improve their accuracy and effectiveness
I’ve intentionally kept this overview brief, as MLOps is a vast topic worthy of a dedicated blog post. I also view MLOps as the next evolution of DevOps, revolutionizing how organizations operationalize AI.
Conclusion
This blog post has explored the evolution of models, from traditional approaches through machine learning to the transformative impact of foundation models. It highlighted the mathematical foundations underlying these models and emphasized the critical role of data quality in influencing model and algorithm selection. Additionally, discussed how these concepts integrate with software engineering practices and the broader technical landscape.
The primary goal has been to clarify the role models play in AI and software engineering. While not every enterprise will build models or develop algorithms from scratch, it is essential to understand where models fit within your technical architecture and their impact on business outcomes.
To close with an analogy: models are like powerful engines beneath a car’s bonnet. Just as a high performance racing engine isn’t necessary for a daily urban commute, selecting the right model is crucial to align with your business needs and long term viability. Ultimately, the future belongs to organizations and leaders, who can harness the evolving landscape of models and foundation models to architect intelligent, scalable, and trustworthy software systems.